-
Development of an integrated, deep learning-based system to support the curation of biomedical databases
Müller Group, Heidelberg Institute for Theoretical Studies, Service Center: de.NBI Systems Biology Service Center - de.NBI-SysBio
The BMBF-funded DeepCurate project (Computational Life Sciences (CompLS) -Deep Learning in Biomedicine) will support the previously manual curation process of scientific publications in biomedical databases using the SABIO-RK database as an example. SABIO-RK is a database for biochemical reactions and their kinetic properties. The curation in SABIO-RK mainly comprises the manual extraction as well as the standardization and annotation of data from the scientific literature to provide them in a structured, easily accessible and machine-readable form. Scientific publications are often unstructured. Existing automatic natural language processing (NLP) methods do not have the required coverage, robustness, and effectiveness to be used for the curation of high-quality databases. However, current advances in deep learning-based NLP allow the support of the curation process by using methods of automatic information extraction and thus make the process more effective and efficient. However, deep learning needs training data. DeepCurate explores innovative ways to use training data of various modalities (texts, images, eye trackings). In combination with current deep learning approaches, which can particularly benefit from multi-modal input, DeepCurate will be a very powerful tool that can also be adapted to other manually curated biomedical databases because it is not dependent on specific database models, ontologies, and scientific domains.
A first publication uses data from the SABIO-RK curation process to generate useful training data for deep learning approaches. Without the curation knowledge generated and maintained in de.NBI for more than a decade, the generation of such training data would be very expensive and time-consuming. The project exemplifies the interaction between service and research activities.
For further information, please visit SABIO-RK.
Funded by: BMBF, FKZ 031I0204
Search projects by keywords:
-
Scalable Curation and Genome Function Prediction by the aid of Artificial Intelligence
Overmann Group, Leibniz Institute DSMZ, Service center: Center for Biological Data – BioData
The rapidly increasing amount of data produced in science comes with new opportunities in analysis but also with new challenges in processing, interpreting, and storing data. The risk is high that large amounts of the data are only superficially analyzed and are being dumped on local storage without sufficient metadata enabling reuse of the data. Moreover, publication numbers rise quickly, but the data aggregated are difficult to access and not available for large scale analysis.
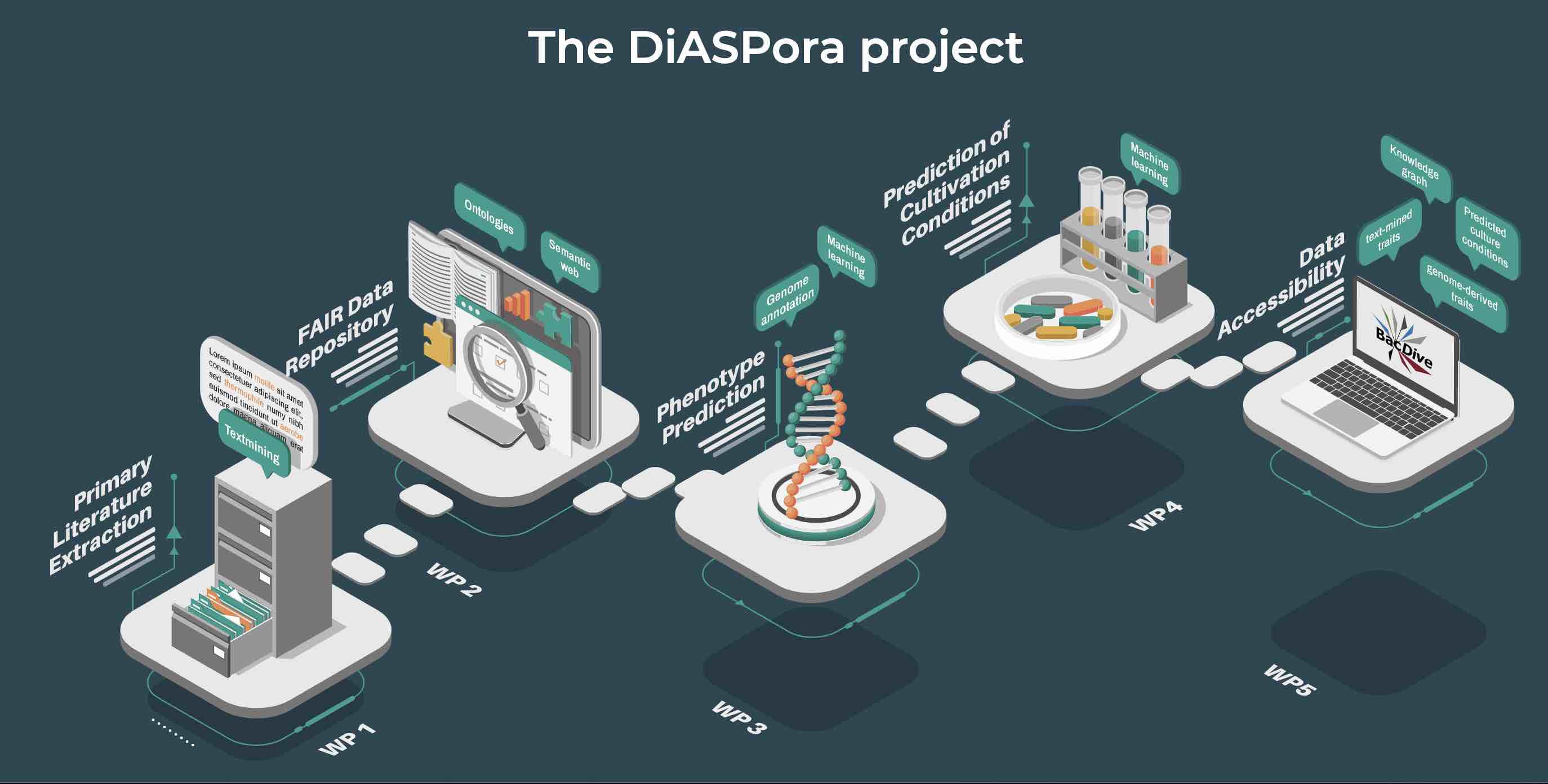
In a new approach (DiASPora project), the Leibniz Institute DSMZ is synthesizing information for bacterial species from diverse sources, together with the TIB Hanover, and ZB MED Cologne and publishes these in the database BacDive.
So far, the curation of scientific data is still a largely manual process that does not scale with the increasing amounts of data published every day. Therefore, workflows are developed that apply text mining combined with machine learning approaches including deep neural networks to automatically extract data for more than 150 microbial data types from literature. To attain high quality and correctness of the extracted data, a manual curation feedback loop will be integrated into the text mining pipeline, which enables to train the AI and thereby successively improve the quality.
The increasing availability of genomic data enables the prediction of bacterial traits based on genome annotation data. To achieve high quality in function prediction, classifiers are trained and tested with phenotypic data from BacDive and standardized genome annotations. An iterative optimization process including manual curation will retrieve the best models for a number of traits, allowing us to make predictions with a high confidence level for so far poorly studied bacteria.
All data that reach a high level of confidence will be standardized and published in BacDive (de.NBI tool) in a machine-interpretable format, ready for reuse and large-scale analysis.
For further information visit the following websites for DiASPora project and BacDive.
Source: https://diaspora-project.de/
Search projects by keywords:
